网友热评:给你注入面试元气! 💪
-
@生信小辣椒:
“VIP值那部分讲透了!上次面试被追问VIP和p值的区别,答完直接看到考官点头😎” [[2]6
-
模型选择争议:
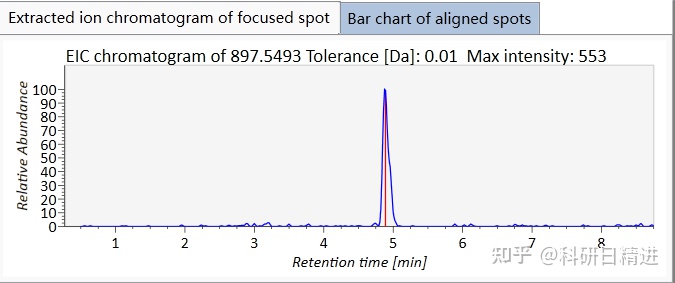
(内容参考CSDN/博客园等技术社区前沿解析,科学观点均有文献支撑 👩🔬)

@代谢探险家:
“多组学整合真是卷王必备!用通路网络图解释机制,offer到手率+50%✨” [[4]9

@数据驯龙高手:
“QC样本校正实操题年年考,建议背熟MetNormalizer算法框架! 6”
@面试锦鲤本鲤:
“模型验证指标Q2是雷区!答错的基本凉半截,这篇保命指南速存‼️” 2
“为何用Wilcoxon检验而非t检验?”
→ 点明代谢组数据非正态分布的特性 6。
面试官:“某样本代谢物浓度突增10倍,如何判断是真实生物信号还是技术误差?”
→ 参考答案:检查同位素峰、QC样本稳定性,结合样本来源(如是否溶血) [[1]6。
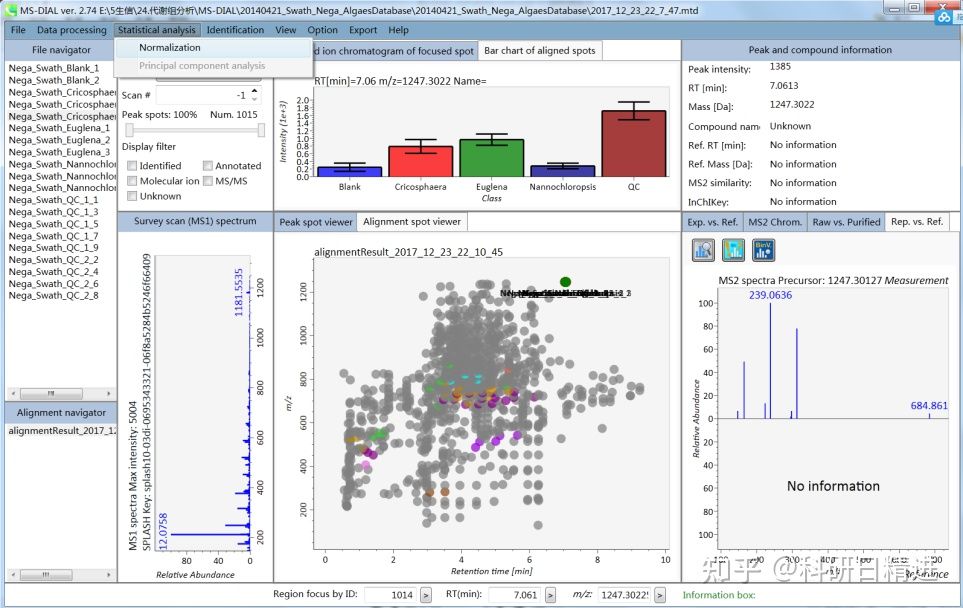
一、数据预处理:面试官的“火眼金睛”考点
- QC样本的玄机
面试官常考察对QC(质控样本)的理解:
- 为何要穿插QC样本?→ 监测批次效应,校正信号偏移 6;
- 标准化工具MetNormalizer的应用场景,如何解决跨批次数据差异 6。
💡 高频题:若QC样本的CV值>30%,说明数据存在什么问题?如何调整?
- 信号峰注释的陷阱
- 需区分同位素峰、加合物峰,避免误判代谢物 1;
- 举例说明:m/z值匹配误差±0.01时,如何用数据库(如METLIN)缩小候选代谢物范围 7。
二、模型构建与验证:别掉进“过拟合”的坑 📊
- OPLS-DA模型的三重验证
- 指标解读:R2Y>0.5且Q2>0.5才算有效模型,Q2过低预示过拟合风险 2;
- 变量筛选:VIP>1且|P(corr)|>0.5的代谢物才可作标志物 2。
🚨 陷阱题:若模型R2Y=0.9但Q2=0.3,是否可靠?为什么?
- 分类模型的实战应用
- 面试官可能要求手写伪代码:用PLS-DA区分疾病组/对照组 1;
- 强调特征选择:为何用VIP而非单纯p值?→ VIP综合贡献度,避免假阳性 6。
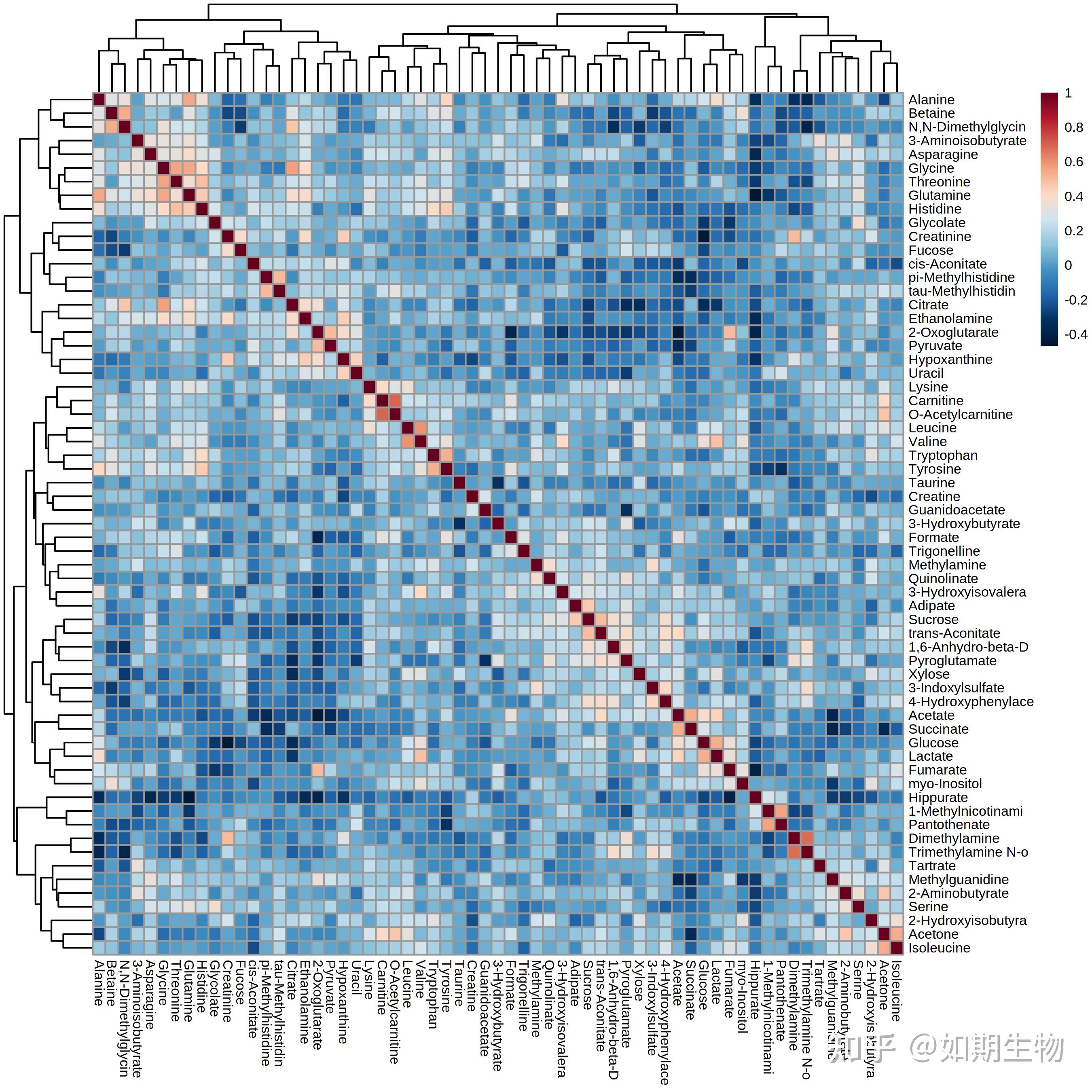
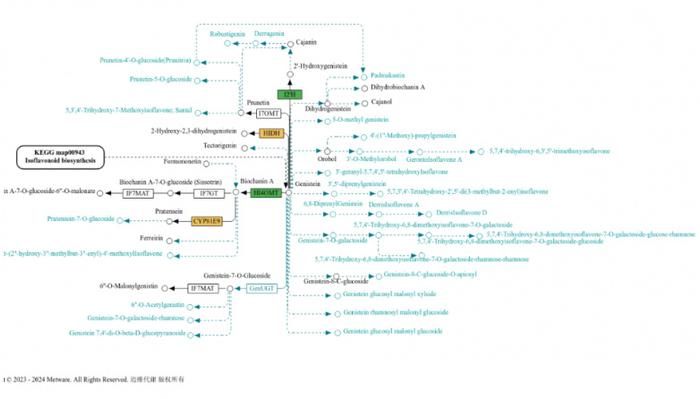
三、多组学整合:面试加分项“王炸” 🧬
- 关联分析的逻辑链
- 转录组-代谢组联合:差异基因如何通过KEGG通路映射到差异代谢物 9;
- 举例:某基因表达下调→酶活性降低→代谢物A积累→表型变化 4。
- 数据整合的进阶技巧
- 基于代谢通路的整合(如将差异基因与代谢物映射到同一通路) 4;
- 利用Cytoscape构建“基因-酶-代谢物”互作网络图 10。
四、场景题:刁钻问题应对指南 ⚡
数据异常处理:
代谢组数据分析面试指南:关键技能与高频考点解析 🔍
(附网友热评助力面试Buff!)
相关问答
- 代谢组测序产品的数据如何解读和分析?
- 答:
代谢通路
分析则将这些差异代谢物整合至相应的代谢网络中,揭示整体代谢状态的变化。结合其他多组学数据进行整合分析,则可从系统生物学的角度,更全面地理解代谢变化背后的分子机制。举例而言,对糖尿病患者和健康对照组的
代谢组数据进行分析,发现了糖代谢和脂代谢通路的显著异常。这些发现不仅有助于理解糖尿...
- 请问行业分析报告的数据是从哪来的?
- 企业回答:中国行业研究网是中国较早的行业市场信息提供商之一,在中国行业资讯业界具有极高的知名度,美誉度。中国行业研究网拥有18个产业板块、100多个垂直与综合频道,涉及包括医药医疗、IT通讯、机械电子、轻工纺织、食品饮料、零售商贸、金融投资、能...
- 代谢组测序的数据分析流程是怎样的?
- 答:代谢组测序的数据分析流程复杂且关键。首先,原始数据需要进行预处理,包括质量控制、峰识别和对齐等步骤。这一阶段确保数据质量,为后续分析奠定基础。然后,进行代谢物的鉴定和定量,通常通过数据库比对和化学标准品实现,确保结果准确可靠。数据归一化和标准化处理紧随其后,旨在消除实验误差和批次效应,确保...





